Turning FEMA Transaction Data into Structured NLP Insights with Conode.ai
A hands-on, visual walk-through of turning messy federal transaction data into structured insights using Conode’s no-code Graph AI platform.

Introduction
In an era where federal agencies generate vast volumes of complex data, the ability to derive meaningful insights from unstructured information is paramount. This post explores how Conode.ai’s no-code Graph AI platform can be used to semantically enrich and structure federal transaction data — specifically, FEMA awards from USAspending.gov. We demonstrate how modern NLP techniques, particularly contextual embeddings, can be harnessed to create powerful machine learning features and intuitive visual insights without writing a single line of code.
Much like the shift to SaaS in education, we’re seeing a parallel in data science: the rise of platform-based tooling that abstracts away infrastructure complexity, enabling analysts and subject matter experts to focus on what matters — insight and decision-making.
Why NLP and Contextual Embeddings Matter
In classical NLP, techniques such as bag-of-words or TF-IDF offered basic ways to quantify text. However, these methods lack context. For example, the word relief could refer to disaster aid, sculpture, or even financial policies — depending on its surroundings.
Contextual embeddings, pioneered by models like BERT, GPT, and ELMo, solve this by encoding words within their surrounding sentence. This allows for:
Rich semantic understanding
Disambiguation of polysemous terms
Transfer learning from large pre-trained language models
✅ Technical Accuracy Note: Contextual embeddings assign dynamic vector representations based on context. Unlike static embeddings (Word2Vec, GloVe), they generate distinct outputs for the same word in different sentences.
Project Architecture: From Raw CSVs to Embedding-Driven Graphs
Step 1: Importing and Inspecting FEMA Data
Data source: USAspending.gov
Format: CSV
feature columns:
Recipient Name,Transaction Amount,logins, days_since_transaction,transactions_last_30dObjective: Extract semantic insight from the
Recipient Namefield and unify messy entity names inRecipient Name.
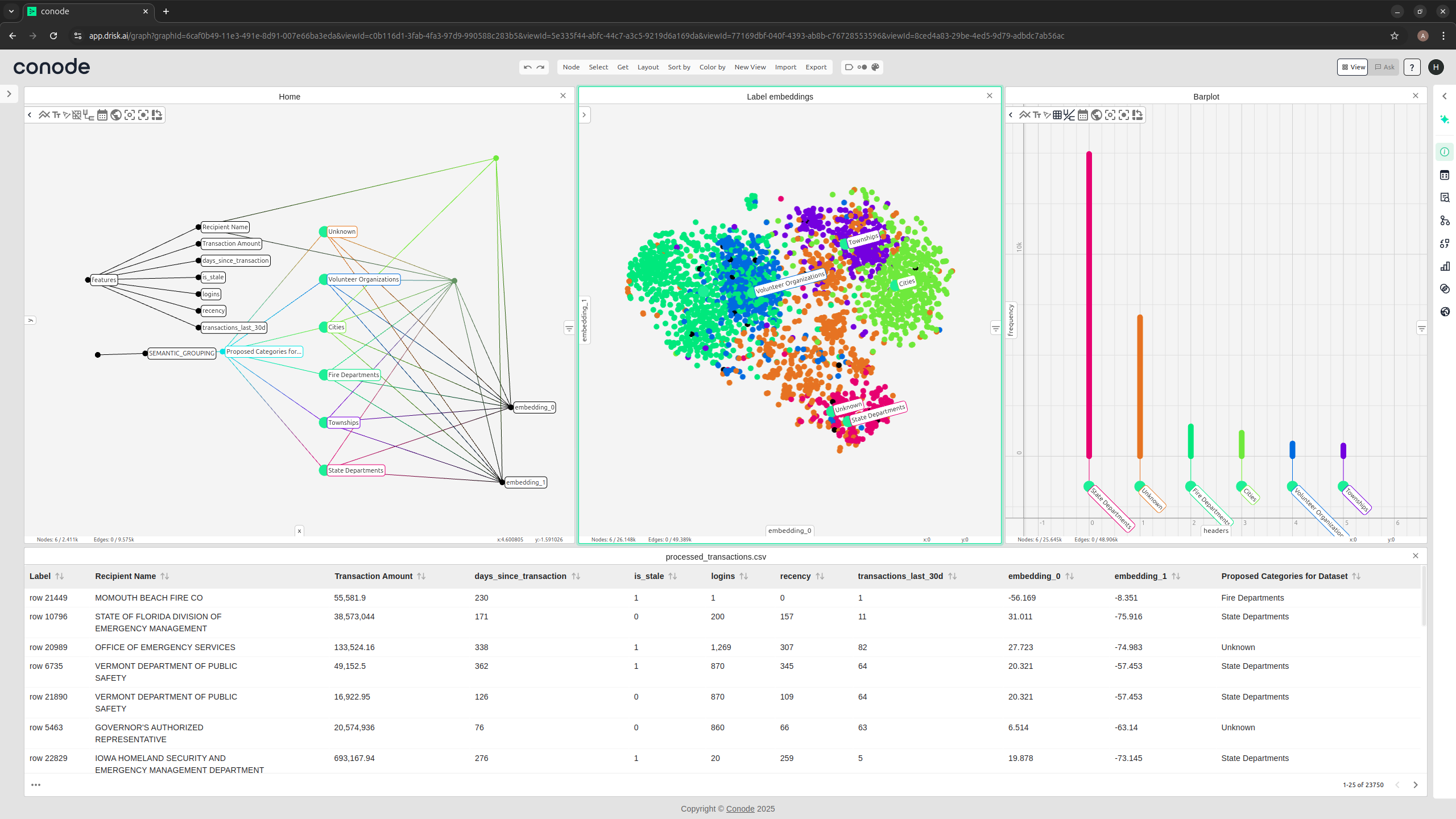
Step 2: Semantic Entity Grouping
Conode’s NLP backend (powered by contextual embeddings) automatically clusters similar recipient names using approximate string matching and semantic similarity.
Example:
“Springfield Emergency Relief Org” and “SPRINGFIELD EMRGCY RLF ORG INC” are grouped into a single semantic node.
🔍 Under the hood, this likely involves vector clustering in embedding space (e.g., cosine similarity + agglomerative clustering).
Step 3: Creating the Embedding Space
Conode embeds textual descriptions into a high-dimensional space, and projects them to 2D using techniques like UMAP or t-SNE. This enables visual inspection of:
Clusters of similar award purposes
Outliers or mislabeled data
Patterns by agency or disaster type
⚠️ Note: While embeddings are high-dimensional, dimensionality reduction is used for visualization. This step does not preserve all semantic relationships.
Step 4: Propagating Semantic Categories
Users can assign labels to clusters manually or semi-automatically:
“Volunteer Organizations”
“Townships”
“Unknown”
Allowing our categories and values to be propagated across the dataset, we are able to generate features for downstream ML tasks or dashboards.
Step 5: Visual Exploration & Insights
Assign colors to different semantic groups.
Navigate the knowledge graph to explore your unknowns.
Step 6: Visual Enhancements
Customize layout, spacing, fonts, tooltips.
Add charts: bar plots of recipient categories, or timelines of funding waves.
Take snapshots or create a slideshow view to tell a data story.
Graph-Based EDA: Visual + Intuitive
Conode’s graph AI interface allows users to:
Traverse entity relationships
Group or collapse nodes based on similarity
Apply color-coding for visual segmentation
This graph-based approach is particularly valuable for data exploration, helping identify funding overlaps, regional distributions, or previously unseen relationships.
Potential Pipeline Extensions for ML Integration
While our post ends with visualization and insight, the embedding-based features created can be used for:
Classification: Predicting funding purpose or fraud likelihood
Clustering: Unsupervised segmentation of recipients
Anomaly Detection: Spotting unusual funding patterns
⚙️ Exported embeddings (usually in
.csvform) can be plugged directly into Scikit-learn, XGBoost, or PyTorch workflows.
Final Thoughts: Conode.ai & NLP
Incorporating NLP and contextual embeddings into machine learning pipelines unlocks new frontiers in feature engineering. By capturing the nuanced meanings and relationships embedded in text data, these techniques enable the development of more intelligent, adaptable, and interpretable models.
By combining contextual NLP with graph-based visualization, platforms like Conode.ai provide analysts with capabilities once reserved for full-stack ML engineers — from entity disambiguation to interactive, semantic exploration.
This marks a broader shift in data science tooling: abstraction without compromise. Conode.ai removes the burden of infrastructure, modeling orchestration, and pipeline engineering — allowing data professionals to focus on interpretability, pattern recognition, and decision support.
Key Benefits Recap

Embrace the power of no-code NLP and contextual embeddings — and elevate your models with richer features, faster workflows, and more actionable insights.